Open Source
- Dataset: USIM is publicly available on HuggingFace 🤗
- Model Weights: U0 model weights are available on HuggingFace 🤗
- Code: Model code is available on GitHub
- Simulation Environment: Available on GitHub
- Latest Results: Updated on arXiv
Abstract
Underwater environments pose unique challenges for robotic navigation and manipulation, while studies on general-purpose intelligence for multi-task execution remain scarce. To address this gap, we present USIM, a simulation-based Vision-Language-Action dataset comprising over 905K frames from 2,275 trajectories, totaling approximately 25 hours of BlueROV2 interactions. Building on USIM, we propose U0, a VLA model featuring a convolution-attention-based perception module with target pose estimation to enhance spatial awareness. U0 achieves state-of-the-art performance: an overall online success rate of 43.1%, marking a 5.5% improvement over competitive baselines, with navigation tasks reaching 87.5%. These results validate the feasibility of general-purpose underwater robotic intelligence.
Method
Overall Framework. Diverse underwater scenarios and a BlueROV2 robot equipped with a manipulator are first constructed within the Stonefish simulator. Data collection and control are managed via ROS, yielding the USIM dataset of 905K frames (approximately 25 hours) across 20 tasks. The U0 model is then designed, which integrates a DiT action module and a CAP module, generating concurrent target perception and robot action outputs.
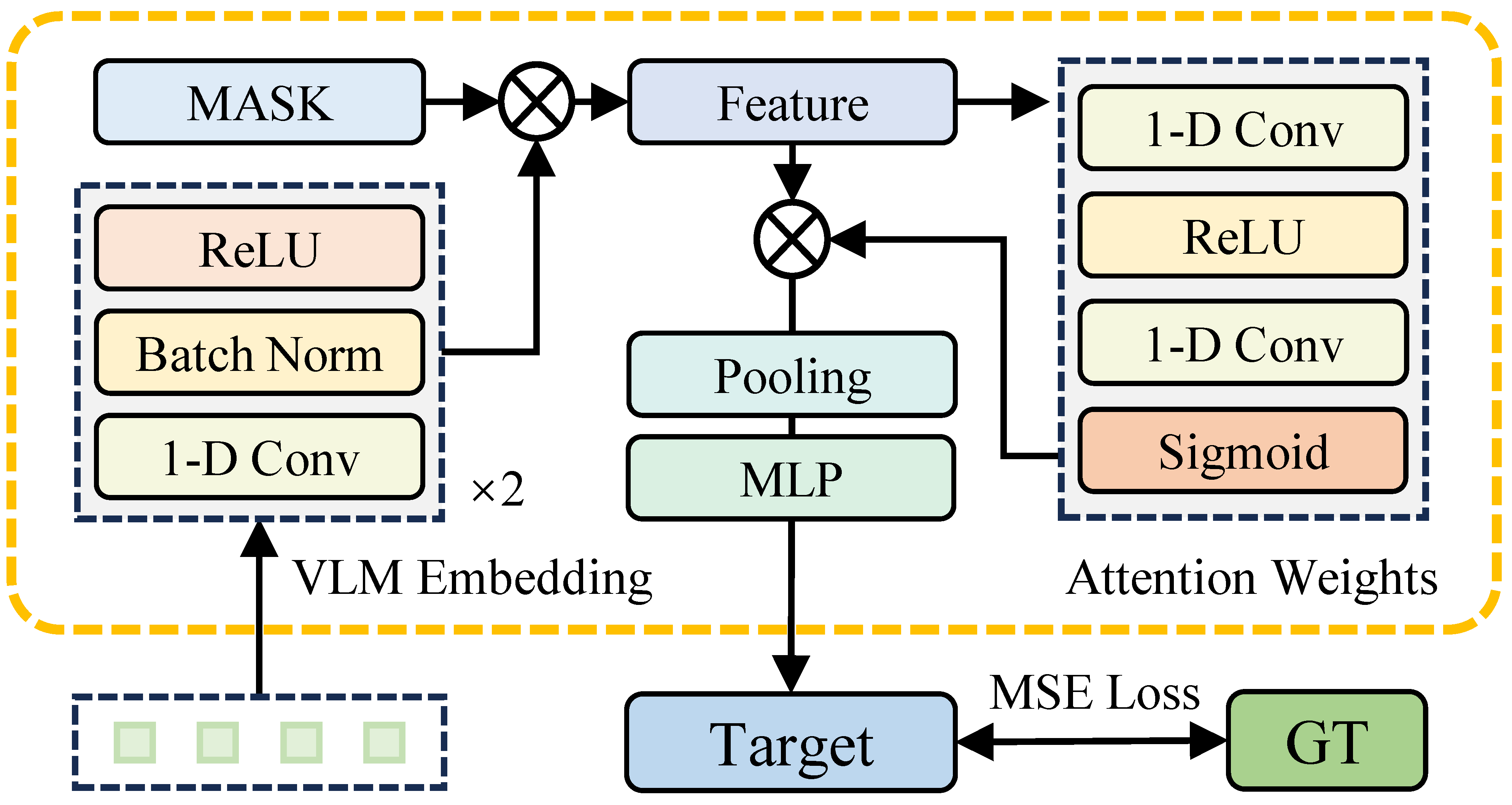
The structure of the CAP module. Through combining convolutional layers and attention pooling, feature focus is refined for enhanced perception.
Underwater Scenarios

Seabed

Seabed pipeline

Industrial pool

Solar charging station

Lake

Open sea surface

Underwater factory

Modern shipwreck

Ancient shipwreck
Seabed
Seabed pipeline
Industrial pool
Solar charging station
Lake
Open sea surface
Underwater factory
Modern shipwreck
Ancient shipwreck
Results
| Model | Navigation | Grasping | Transporting | Tracking | Overall SR (succeed/total) |
||||
|---|---|---|---|---|---|---|---|---|---|
| SR ↑ | SPL ↑ | SR ↑ | ASD ↓ | SR ↑ | SSR ↑ | SR ↑ | MTD ↓ | ||
| OpenVLA | 25.6% | 0.70 ± 0.21 | 0.0% | — | 0.0% | 0.0% | 5.0% | 4.02 ± 0.00 m | 6.0% (42/700) |
| π0.5 | 46.9% | 0.87 ± 0.18 | 37.1% | 97.3 s | 20.0% | 45.0% | 10.0% | 4.52 ± 0.06 m | 37.6% (263/700) |
| GR00T N1.5 | 76.3% | 0.69 ± 0.21 | 24.0% | 92.3 s | 15.0% | 30.0% | 30.0% | 4.16 ± 0.14 m | 35.6% (249/700) |
| U0 (Ours) | 87.5% | 0.71 ± 0.23 | 30.0% | 87.6 s | 25.0% | 45.0% | 40.0% | 3.61 ± 0.35 m | 43.1% (302/700) |
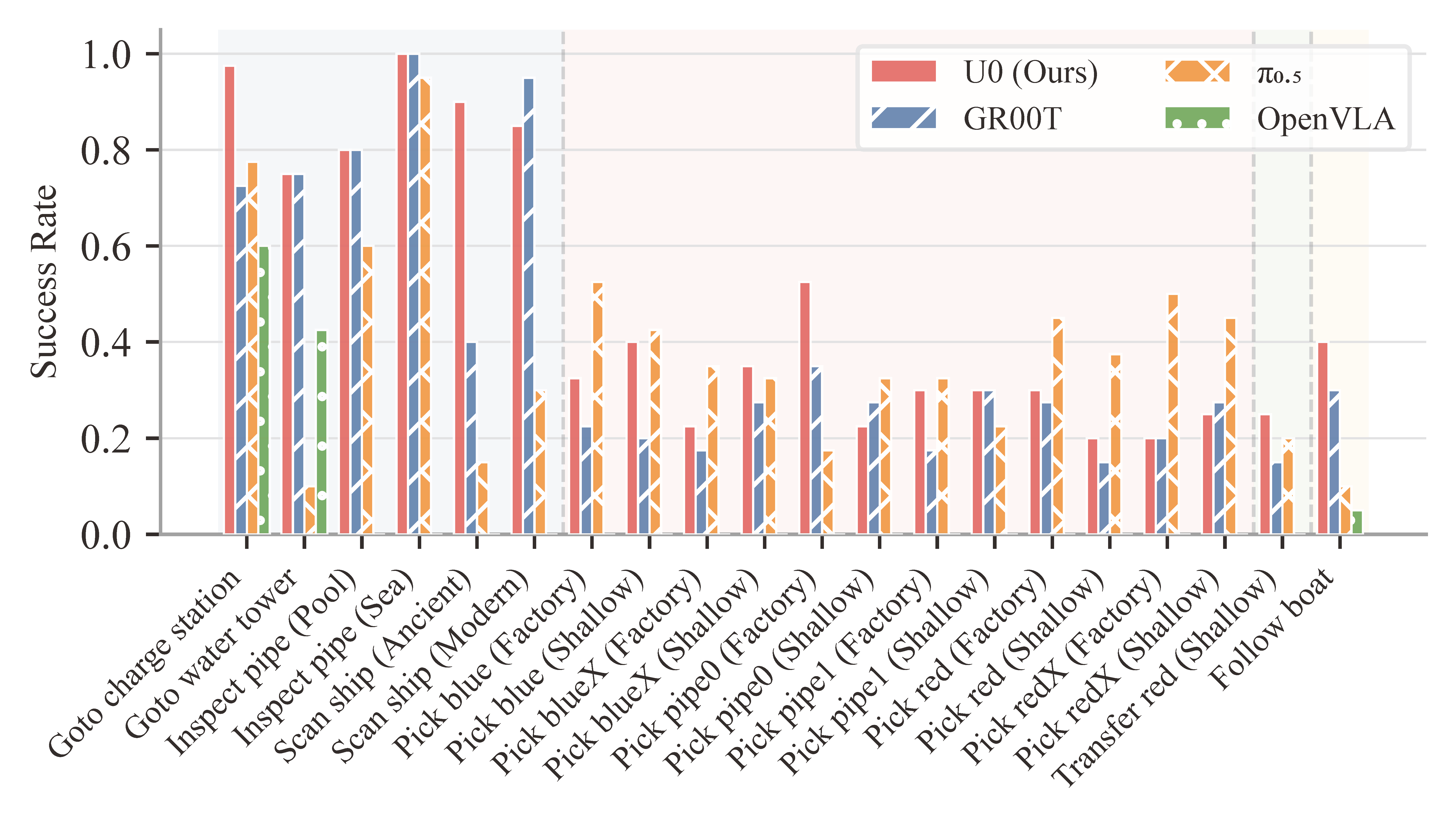
Model Performance Comparison. Breakdown of success rates across 20 individual tasks.
BibTeX
@misc{gu2025usimu0visionlanguageactiondataset,
title={USIM and U0: A Vision-Language-Action Dataset and Model for General Underwater Robots},
author={Junwen Gu and Zhiheng Wu and Pengxuan Si and Shuang Qiu and Zhentao Zhang and Yukai Feng and Luoyang Sun and Laien Luo and Lianyi Yu and Jian Wang and Zhengxing Wu},
year={2025},
eprint={2510.07869},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2510.07869},
}